Deep dive into the Write Path: from the Memtable to Level 0¶
This section covers HedgeDB’s write path: how data flows from a put(key, value) call to a Level 0 SST on disk, with a focus on the concurrency design that keeps parallel writes fast.
Memtables and WALs¶
Brief recall¶
The Memtable is the in-memory data structure of the LSM-tree holding the most recent Key-Values. Similarly to an LRU-Cache, the Memtable is the first area being checked on look-up operations. It also acts as a buffer to amortize insertion cost; of course, it cannot grow indefinitely, but only up to a pre-defined capacity, usually in the 16-128 MB range. After it gets full, the Memtable is flushed to disk (and transformed to an SST). This fresh SST file is now ready to be pushed to LSM-tree Level 0.
To ensure persistency, every new insertion is appended to a file on disk, the Write-Ahead Log: this way, on crash or power-loss events, replaying the WAL allows restoring the database’s state just before it crashed.
Memtable and WAL organization¶
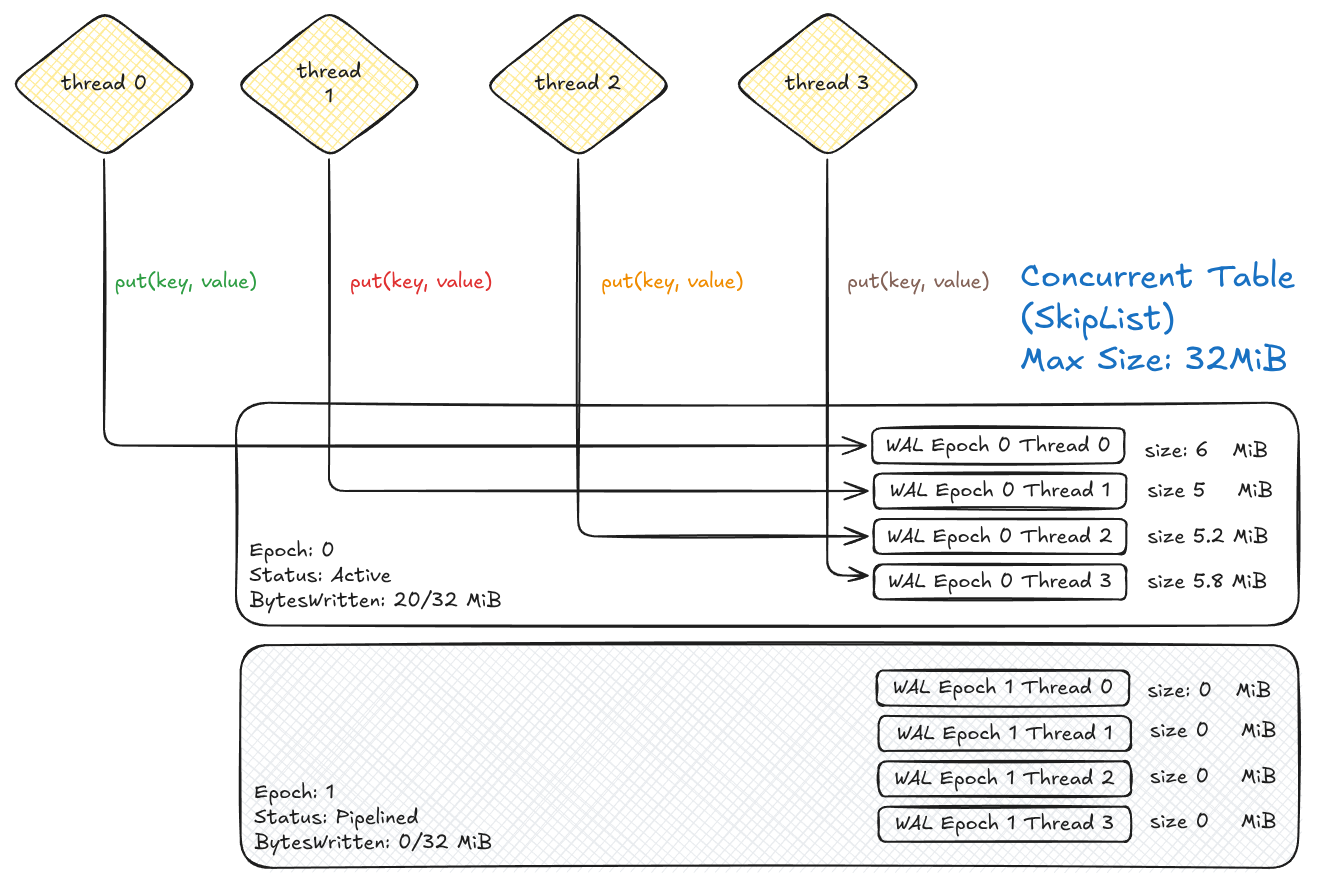
In the image above is exemplified the Memtable WAL architecture in HedgeDB: the Memtable is shared and accepts parallel writes by multiple threads. Each thread appends to its own WAL file, minimizing lock contention at file-descriptor level.
Double-Buffered Memtable¶
In HedgeDB every insertion is directed to the Active Memtable (and the associated WALs), but there is also a second Pipelined Memtable. Both Active and Pipelined Memtable have their own set of WAL files. When the Active Memtable is scheduled for being flushed, the Pipelined gets promoted to the Active (which is implemented just as an exchange operation) and the Writers can continue operating with very negligible wait time.
This impacts performance positively: the job of allocating the Pending and resetting the WAL files involves a few syscalls that might be expensive, so the Pending Memtable is prepared asynchronously from a background worker.
The Put Operation state machine¶
The following diagram describes the Put operation state machine needed for coordinating the Memtable
updates and flushes between parallel threads.
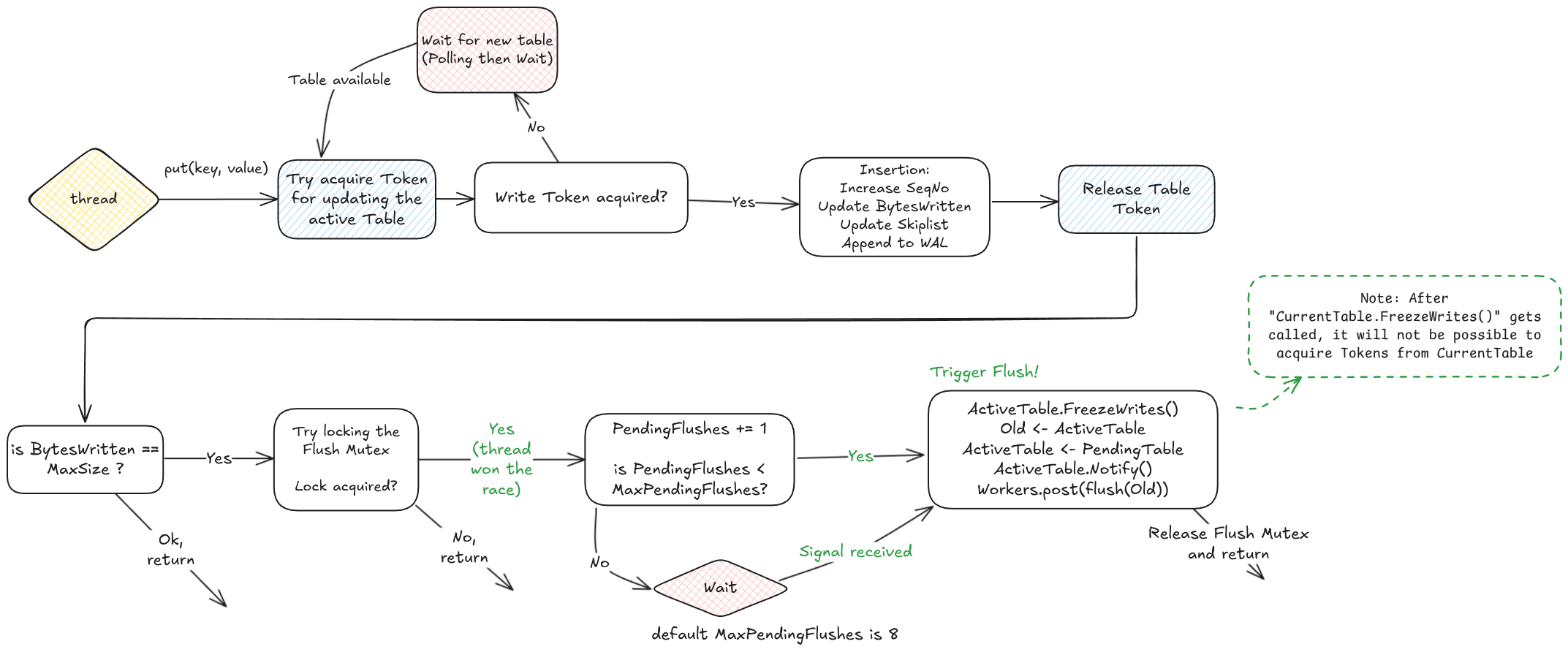
The actual implementation in memtable.cc might slightly differ from what is illustrated here.
Insertion steps¶
1. Acquire Write Token¶
The first step is acquiring a Write Token for updating the Memtable.
This step fails if this Memtable was “frozen”: after freezing it, any further insertion is forbidden. Memtables are frozen right before triggering a flush: of course, the Flusher Worker expects that the Memtable is in a Read-Only state.
The Write Tokens are implemented using a synchronization scheme inspired from Read-Copy-Update: rw_sync. Its implementation is discussed in the Writers-Reader synchronization section
2. Wait for the new Memtable¶
In case the Token acquisition fails, the thread waits for the Pipelined Memtable to become Active. In detail, it first tries polling for the new Memtable for a fixed number of retries (with max 4 retries); if the new Memtable is not available yet within this limit, the thread yields control to another coroutine until it’s signaled.
3. Skiplist & WAL Insertion¶
The actual insertion takes place: the (global) Sequence Number is increased, the Bytes Written count for the Active Memtable is updated, the Key-Value pair is inserted into the Skiplist and the entry is finally appended to WAL.
4. Token Release¶
The Write Token is released, and if a Flush operation is triggered, it will commence the Flush as soon as every thread has released its token.
Trigger Flush steps¶
When the Active Memtable reaches full capacity, the flush operation is triggered but this involves some synchronization work between threads.
The “Happy Path” is implemented to be as fast as possible through a series of simple atomic operations.
1. Buffer Capacity Reached¶
If any thread detects that the number of Bytes Written (written to the Active Memtable) exceeds the configured Max Size, it will try to trigger the flush job of the currently Active Memtable onto the Flusher Workers Pool.
2. Exclusive Trigger¶
More threads might try to trigger the flush procedure, but only the one which wins the race will (the behavior is similar to std::call_once).
3. Pending Flushes Check¶
The thread increases the number of Pending Flushes, i.e. the number of Memtable that are queued for flush. The Flush
operation will not be triggered if the Pending Flushes counter is above the Max Pending Flushes (as from configuration)
threshold. In this case, the thread will wait until a slot is available. The counter and the signaling are implemented
through a tmc::semaphore.
Notice that this operation blocks the current coroutine; also, since the next step is exchanging the Active Memtable with the Pipelined, this might backpressure into blocking any thread from doing further insertions.
This might happen if the underlying storage device is not keeping up with the inbound data flow, and new writes are stopped to protect main memory consumption.
4. Trigger Flush¶
Assuming that the Pipelined Memtable is already available (if not, the thread waits for it), The Active Memtable is frozen in order to prevent new writes (freezing is a single atomic operation). Then, the Active Memtable is exchanged with the Pipelined Memtable, that in turn becomes the Active one. If there was any waiting Writer thread, now it is free again to let the data flow.
Finally, the actual Flush-to-disk job, in which the Memtable is written to disk as SST file, is deferred to the Flush Worker Pool (see next section) and the thread can go back to other tasks.
Flusher steps¶
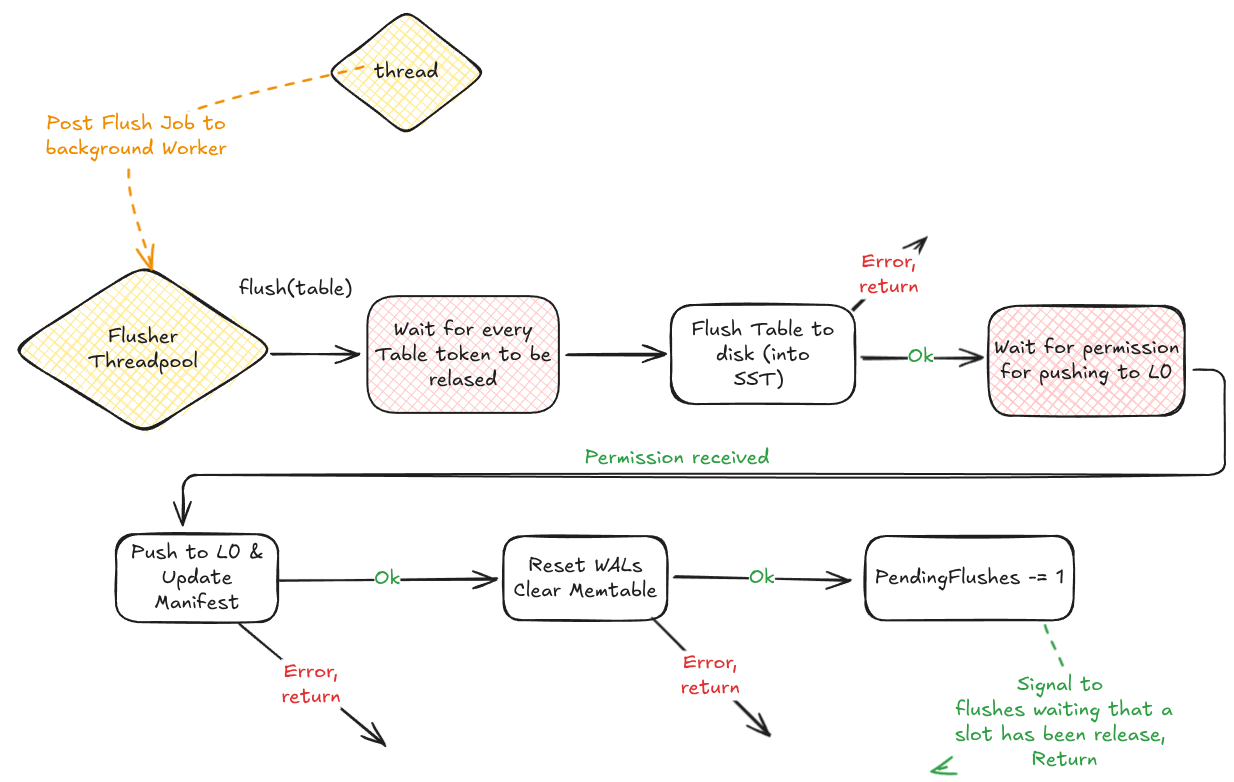
1. Wait for Memtable to be in Read Only¶
Before starting to flush the Memtable to filesystem into an SST, the Flusher must wait any Write Token to be released. Following, because the Memtable was frozen, the Write Token cannot be acquired anymore. This implies that the time spent waiting is negligible.
2. Flush to SST¶
The Flush Worker actually writes the Memtable to disk. The process consists of iterating for every key-value (the Skiplist is already ordered) and progressively building the SSTs Index Blocks.
3. Wait for permission for pushing to L0¶
In order to increase performance, multiple Workers can process the Flush jobs in parallel; however, each LSM-Tree level is organized as a vector of SSTs, inversely sorted by SST age (the most recent SST is the last item). In order to keep L0 temporally consistent, the Workers must push following the respective Memtable arrival order. To enforce this constraint, a permission passing scheme is adopted.
4. Manifest Update¶
The Manifest file, containing the mapping between LSM-tree levels and files, is updated and fsync-ed.
5. Reset WAL files & clear Skiplist¶
Now that the SST has been built, and the Manifest updated, the Memtable can be considered fully persisted. The WAL files can be reset and are ready to be reused, and the memory allocated by the Skiplist is freed.
6. Release PendingFlushes¶
The last step is releasing the PendingFlushes semaphore. This signal might potentially unlock a coroutine waiting on it, thus relieving backpressure.
Memtable implementation in HedgeDB¶
HedgeDB uses a Concurrent Skiplist (src/db/skiplist/)
as the Memtable.
The implementation is extracted from Meta’s Folly.
The Skiplist is a natural fit for Memtables and a typical choice among LSM-tree-based databases:
it is a sorted associative data structure, it is “upgradable” to support concurrent reads and writes,
and provides O(log n) lookups and inserts. While this algorithm
is technically not lock-free, it basically behaves as if it were but with less complexity.
See the Failed experiments section for the path that led to this choice.
Details about the Write-Ahead Log¶
Files organization¶
HedgeDB uses a per-thread WAL file approach for zero inode contention or file descriptor lock at the filesystem level and for write parallelism: NVMe SSDs can easily handle this.
When the database is initially created, a number of WAL files are generated
with pre-allocated size (fallocate with the KEEP_SIZE flag), each of
size memtable_target_size / num_writer_threads.
The total file count is num_writer_threads * (cfg.max_pending_flushes + 2)
(+1 for the currently active WALs and +1 for the WALs associated with the
Pipelined Memtable).
WAL files are pooled and reused across flushes: this way we
avoid the repeated overhead of creating, allocating, and deleting files on
the filesystem, and consequently the need to fsync the base directory.
WAL entry format¶
Entries are appended following this format:
[seq_nr (8 bytes)]
[encoded_key_size (1 byte)]
[key (K bytes)]
[value_size (2 bytes)]
[value (V bytes)]
[xxhash checksum (4 bytes)]
WAL durability and file open-mode¶
WALs are opened in O_APPEND mode, and currently no Direct I/O switch is available. By default,
when a disk-write operation occur, the data gets copied to a system-managed buffer that periodically is flushed (writeback mechanism), hence the disk
usage is optimized because writes happen in bulk. With append-mode, WAL file size is also managed by the file-system, via
metadata updates.
If further durability guarantees are needed, it’s possible to configure each WAL for fsync-ing after every write, or every N bytes.
Why the WAL does not leverage Direct I/O?¶
Despite an overall heavy usage of Direct I/O in HedgeDB, and despite it being proven that, for NVMe SSDs, Direct I/O is the optimal choice for write throughput and latency, we preferred going through the OS managed buffer.
Considering that a least 4KB of data must be written, but I need to append every incoming key-value. This are expected to be smaller than 4KB, (e.g. in the 128-256 byte range).
At this point there are two alternatives:
Keep a 4KiB buffer, and I will issue a write every time a Key-Value pair is received
Buffer everything until a 4KB buffer is filled
There are some issues with both:
With the first, there is a relevant write amplification (e.g. with ~128 key-value pairs, a 4KB write is issued ~32 times!) and it would be too slow
This is fast instead, but if the application crash before the buffer it’s filled, a data loss will occur.
So, while it is true that a write will most likely stay in memory for a while and will hit the disk only later, at least the data has been handled to the OS. Since I’d say that the probability of the system crashing is lower than the probability of the application crashing, we opted to default on this strategy.
Is io_uring helping?¶
Not really: a synchronous pwrite call is used instead of going through the
liburing event loop. This was also experimentally found to be the faster choice.
Fast Writers and Flusher Synchronization with rw_sync¶
Given the lack of “hard” synchronization primitives (e.g. mutex), it might occur that a Flush Job starts running
while the Memtable it operates on is still being modified by another thread.
Flush Worker expects that the Memtable is in a Read-Only state, but how do we enforce this constraint, and how can we coordinate the writers and the Flush Worker, in a way that is also fast and lightweight?
HedgeDB solves this issue using a custom synchronization structure internally called rw_sync, which is a declination
of the Read-Copy-Update, implemented through distributed Reference Counting: the Reader-Writer Synchronizer,
or rw_sync.
This concurrency model has already been described:
Each thread acquires a Write Token before inserting a key-value pair into the Memtable, and release it after,
When a Memtable is frozen, it’s not allowed to acquire Tokens anymore (frozen != read only, frozen does not imply that there is no Token around)
The Flusher waits for every Token to be released
The rw_sync.h template object is implemented based on this scheme.
// include/async/rw_sync.h
struct alignas(CACHE_LINE_SIZE) counter_t {
std::atomic_int64_t c{0};
};
template <typename T>
class rw_sync {
T _obj;
std::atomic_bool _frozen{false};
std::vector<counter_t> _counters;
};
The vector of counters represents whether a thread is currently holding a Write Token.
Notice that each slot of the _counters vector is assigned to one and one only thread. This scheme resembles
distributed reference counting.
The reason behind not using just a single std::atomic_uint64, this way each thread independently owns a
cache line, and false sharing is prevented while acquiring and releasing Write Tokens: no performance degradation
due to CPU’s Cache coherence protocol occurs.
This is how the wrapped object _obj is acquired and released (n.b. this is pseudo-C++):
T* acquire()
{
if (rw_sync._frozen)
return nullptr;
rw_sync._counters[this_thread_idx] += 1;
return &this->_obj;
}
void release()
{
rw_sync._counters[this_thread_idx] -= 1;
}
On the other side, the Reader (i.e. the Flush Worker) checks the reference counter via polling:
rw_sync._frozen.store(true);
auto ref_count = sum[c.load() in this->_counters];
while(ref_count != 0)
{
ref_count = sum[c.load() in this->_counters];
yield();
}
// Every token has been released
// .. Read _obj
Note that after the rw_sync is frozen, the reference count will get to
zero in a matter of moments. Either way, this check is performed from the Flusher
that runs on a background thread. Basically, the overhead is tilted to the Flusher thread: this is not just acceptable,
but even desirable.
Permission Chain for concurrency and temporal consistency¶
The flush procedure has two degrees of concurrency:
Each partition can be flushed concurrently (this is experimentally proven to be relevant for performance)
Multiple Memtable-to-SST flushes can run in parallel (see Partitioning in HedgeDB)
After the Memtable is flushed to SST files, the new SSTs must be added to the LSM tree in chronological order. Inspired by this article, HedgeDB uses a semaphore-based permission chain:
In memtable::_flush:
auto next_can_write = std::make_shared<tmc::semaphore>(0); // Initially locked
auto can_write = std::exchange(this->_can_write, next_can_write);
// Launch flush with permission token
tmc::spawn(this->_flush_inner(..., can_write, next_can_write));
In memtable::_flush_inner:
// ... flush memtable to SSTs ...
// Wait for permission (blocks until previous flush completes)
co_await *can_write;
// ... push SSTs to L0 ...
// Give permission to next flush in chain
next_can_write->release();
This creates a serialized chain where flush N+1 cannot publish its SSTs until flush N completes. This ensures SST epoch ordering is preserved.
A similar scheme is used for parallel compaction within the same partition.
Summary¶
In this section we explored in detail how HedgeDB provides great insertion performance. This is achieved by leveraging a high-performance Concurrent Skiplist, per-thread WAL files, and lightweight synchronization methods inspired from lock-free programming techniques.