Architecture & Design¶
or: How I Learned to Stop Worrying and Love the coro
The Hedge Manifesto¶
HedgeDB started from two motivations: wanting a leaner codebase than the general-purpose engines on offer, and wanting to see how much throughput a modern NVMe will actually give you when you design around it. The principles below follow from those two pressures, and each is less a preference than a consequence of taking them seriously:
Async I/O: Modern NVMes achieve maximum throughput at high Queue Depth (32 or even 64). Synchronous systems leave a lot of resources on the table. The answer is leveraging async I/O systems (
io_uringhas been the obvious choice) paired with C++20 coroutines (or any effective asynchronous compute model) rather than relying on threads or callbacks.Acceptable build times: RocksDB’s compile times are long and its code bloat is real: we don’t need maybe 90% of the features that it carries around, and wanted something leaner.
Write-intensive workloads: high write throughput as one of the primary design constraints.
Uniform key distribution: Our workload, like many others, involves uniformly distributed random keys (like hashes or UUIDs); designing around this constraint opens many optimization opportunities.
Direct I/O: Skipping Linux’ page cache makes the code harder to write, but the effort pays off with more stable latencies and/or higher throughput; this is especially true if the database size is larger than memory.
Reasonable memory footprint: memory usage should be carefully consumed and optimized, but we take advantage of it if performance can be pushed.
Learning opportunity: I believe that reinventing the wheel (or at least trying to) is a fundamental process before acquiring in-depth knowledge of a subject. This paves the way for specialized implementations, custom configurations, or novelties that come out during the process. Through this journey, I learned a lot about RocksDB, LSM-trees, and databases in general, but also about many multithreaded programming techniques and operative systems.
Introduction¶
LSM-Tree: data structure overview¶
RocksDB (and LevelDB before it) pioneered the LSM-tree approach for write-heavy workloads. Most engines like LMDB (or almost any SQL Engine) use B-trees, which are fast for reads but write directly to their sorted on-disk position, so every insert requires a random I/O to find and modify the right leaf page. While very efficient for read operations, for write-heavy workloads this becomes a bottleneck as one single new record might cause 3 page writes. There are approaches to mitigate this, but the write amplification is still high.
An LSM-tree (Log-Structured Merge-tree) instead defers writes and batches random into sequential I/O:
Absorb writes into an in-memory buffer (the memtable)
Flush the memtable when the buffer fills, creating immutable Sorted String Tables (SSTs).
Compact in the background, merging old SSTs to control read and space amplification
The write path involves mostly sequential writes, and basically any form of secondary storage (HDD, SATA SSD, NVMes but even DRAM) exhibits the best throughput at sequential I/O.
The trade-off is that reads become more complex: you may need to check multiple SST files (spoiler: there is an effective work-around for that). But for write-heavy workloads, this is a winning bet.
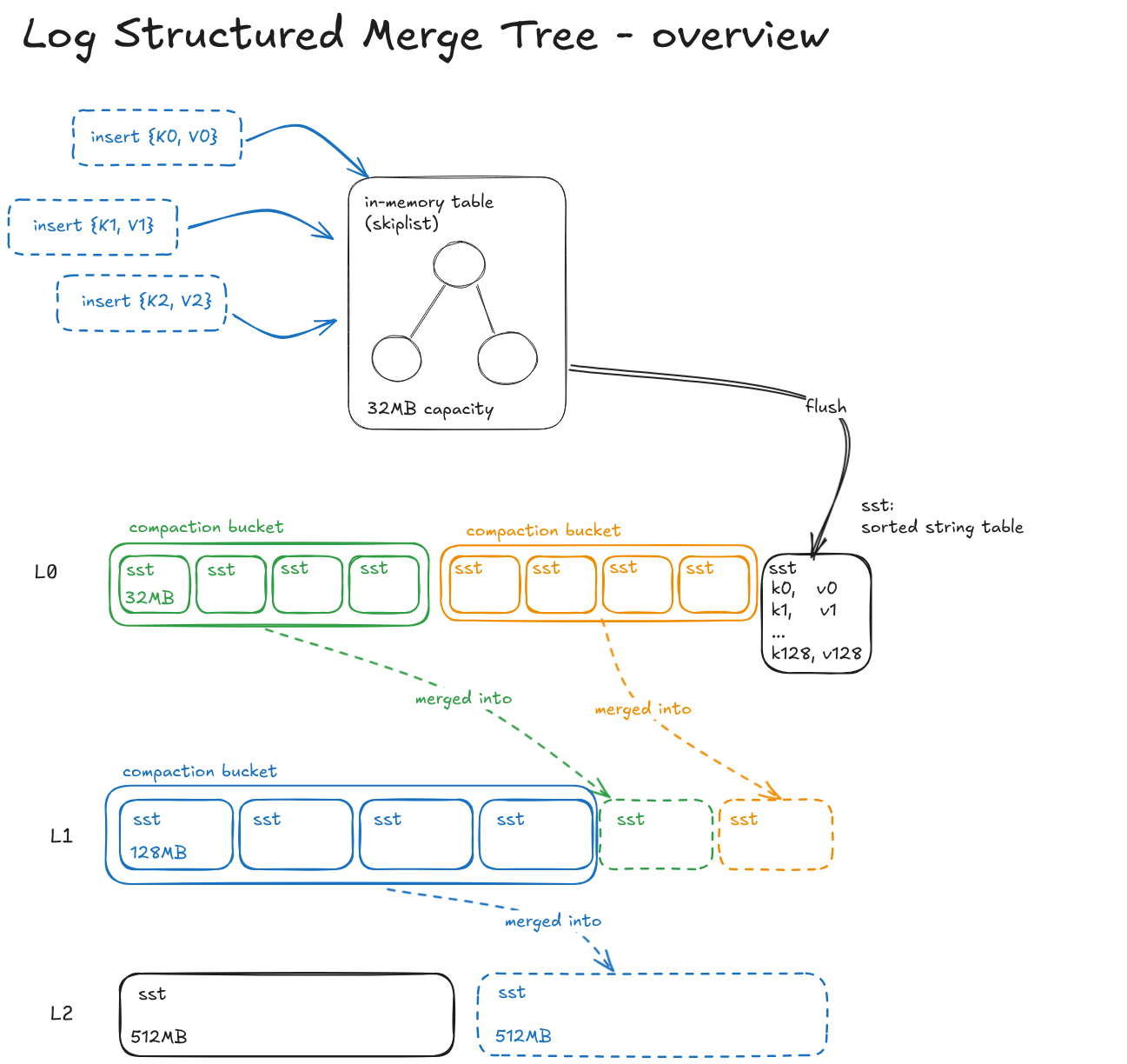
Figure: overview of the LSM-Tree data structure and its components
Sorted String Table files¶
Each SST file is organized in index blocks typically of 4 KiB size. A second-level index (containing one representative key per index block) is pinned in memory. This enables a cheap binary search to locate the right page before any disk I/O. This design allows exactly one random I/O per SST for point lookup/iterator seek.
An approximate membership query filter (specifically, HedgeDB uses quotient filters) is applied to point lookups to skip entire SST files that can’t contain the target key.
Key-Value insertion¶
The insertion of a new Key-Value in the database follows this path:
The Key-Value pairs are inserted into an in-memory data structure referred to as the “memtable” (often it is implemented as a skiplist). At the same time, the Key-Value pair is written on a persistent storage, and this is realized through a cheap write to the Write-Ahead Log (WAL): this ensures data durability under crash or power loss events.
When the memtable exceeds its memory budget (usually in the order of 32 MB), it gets flushed asynchronously to one or more SST (Sorted String Table) files. Flushing refers to the process of transforming a memtable into an SST and streaming it onto the filesystem.
New SSTs enter Level 0 of the tree; if auto-compaction is enabled and some conditions are met, the SSTs are compacted.
Compaction¶
Once created, SSTs are immutable: they can only be deleted after being merged together during compaction: this is strategical for controlling read and space amplification (deleted key-value pairs are dropped). Of course, this comes at the cost of additional write amplification, i.e. how many times 1 byte gets rewritten.
As data is pushed into the database, the SSTs accumulate and this increases read and/or space amplification. Hence, the system spawns some background threads for merging the SSTs together.
SSTs are usually organized in some kind of hierarchy, e.g. they are often split into Levels. The definition of Level varies in literature and between different databases, but usually each Level keeps an exponential quantity of data w.r.t the previous one.
The compaction strategy is the algorithm the SSTs are picked for being merged together, which is mostly responsible for shaping the trade-off between write-read-space amplification. The two most well-known compaction strategies are Leveled Compaction and Size Tiered Compaction, with HedgeDB using the latter.
Deleting records¶
To delete a key-value pair, the database inserts (following the standard insertion path) a special value called a “tombstone”. If a tombstone is found at lookup time, the database responds with “not found”. The value (and the tombstone itself) will actually be discarded when compacted together into the bottommost SST.
Reading back¶
The read path follows the arrival order of key-values, in order to retrieve the most recent value associated with a key:
Query the memtable first (
O(log n)complexity for a skiplist, no I/O is necessary)If no match is found, start probing the SST files from newest to oldest, so a recent write shadows an older one. For each SST:
Probe the AMQ filter to skip files that can’t contain the key
Binary-search the in-memory second-level index to find the index block position where the key could reside
Fetch the index block page (usually 4KB) from filesystem
Decode the index block and search it
First match wins. If it’s not found, or the value is a tombstone, return
KEY_NOT_FOUND
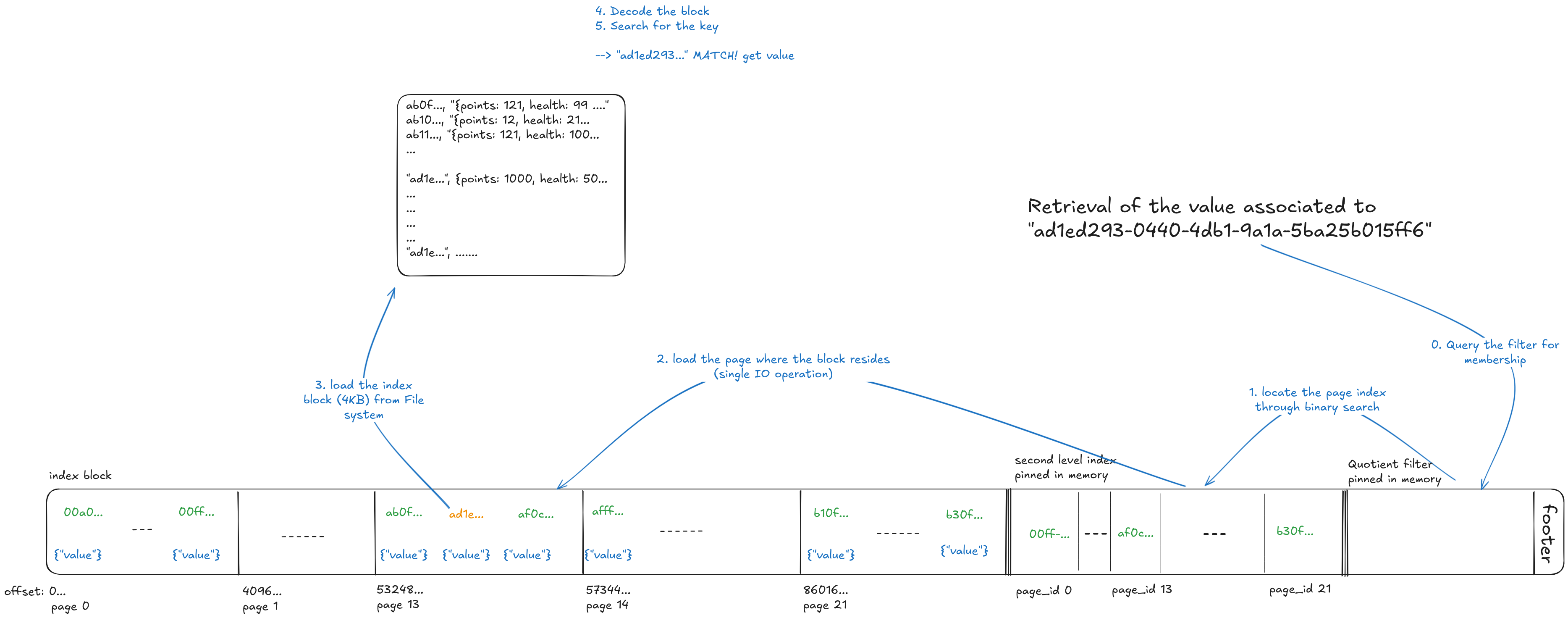
Figure: representation of the point lookup.
How HedgeDB implements this¶
These are the standard LSM-tree building blocks. The internals section covers how HedgeDB specifically implements each of them:
Async model: every I/O is a
co_awaitbacked byio_uring; no callbacks, no thread-per-request.Memtable & WAL: double-buffered memtable with a custom
rw_syncprimitive; per-thread WAL files to eliminate inode contention.SST & partitioning: prefix-compressed 4 KB index blocks, quotient filters, and a partitioned key space for parallel flush and compaction.
Compaction: size-tiered strategy with a semaphore-based permission chain to keep parallel compactions temporally consistent.
Direct I/O:
O_DIRECTon the SST path for predictable latencies and transparent memory usage.