Compaction: Size-Tiered Strategy¶
Without compaction, you’d accumulate thousands of SST files, and reads would need to check every single one. Compaction merges old files, removes duplicates, and reclaims space from deleted keys.
Why Size-Tiered?¶
Unlike “traditional” leveled compaction (which maintains strict size ratios between levels and a bounded number of I/O reads), size-tiered compaction groups files of similar size and merges them together. This produces:
Lower write amplification: files are merged fewer times before reaching the bottom level
Simpler implementation: no strict level-size constraints to enforce, one file per SST
Better fit for write-heavy workloads: writes aren’t stalled waiting for level-size targets
The trade-off is higher read and space amplification:
Leveled compaction has read amplification bounded by
O(|L0| + NUM_LEVELS)random I/O readsSize-tiered compaction’s read amplification is unbounded, and depends on the number of stored SSTs
O(T), which in turns grows logarithmically (because the SSTs in each level grow exponentially).
When does Compaction trigger?¶
Compaction is triggered in three scenarios:
After every memtable flush (if
auto_compaction = true)Recursively after a merge completes, if the target level now has too many SSTs
Manually via
database::trigger_compaction(compact_all)
Size-Tiered Bucket Grouping¶
Within each partition and level, SSTs are grouped into “buckets” to be
merged. The algorithm walks the SST list in epoch order and greedily builds
buckets of at least min_merge_width files, up to max_merge_width. The
output merged SST is pushed to the back of the next tree level.
min_merge_width actually controls the LSM-tree fan-out factor: every SST
in a level is min_merge_width times larger than those in the level below.
Example: Say Level 0 has 10 SST files. With min_merge_width=2 and
max_merge_width=8, the algorithm would emit one bucket of 8 files (merged
together) and leave 2 files behind (below the minimum). On the next
compaction trigger, those 2 remaining files can form their own bucket if
more files have arrived.
Key parameters:
min_merge_width: Minimum SSTs to form a bucketmax_merge_width: Maximum SSTs per bucket
Permission Chain: parallel compactions on the same level¶
… without breaking the database.
When multiple compaction jobs merge SSTs on the same level, they must complete in epoch order to maintain the chronological consistency within the tree.
This can be better explained with an example.
Consider four SSTs in L0: A, B, C, and D, with A being the oldest and D the newest.
Both A and C contain an entry with the key
K, call themK_AandK_C, withK_Cbeing a tombstone entry (i.e. a deletion marker).Two parallel compactions are triggered: A with B, and C with D.
C and D get merged first (into “CD”) and immediately pushed to L1; A and B (into “AB”) follow.
Now the L1 ordering is
[CD, AB].Error: when looking up
K, AB is read first andK_Ais retrieved, butKhad been deleted byK_C!
The solution is the same semaphore-based permission chain used by the flush path: each compaction job for a given level acquires a semaphore from the previous job before publishing its output.
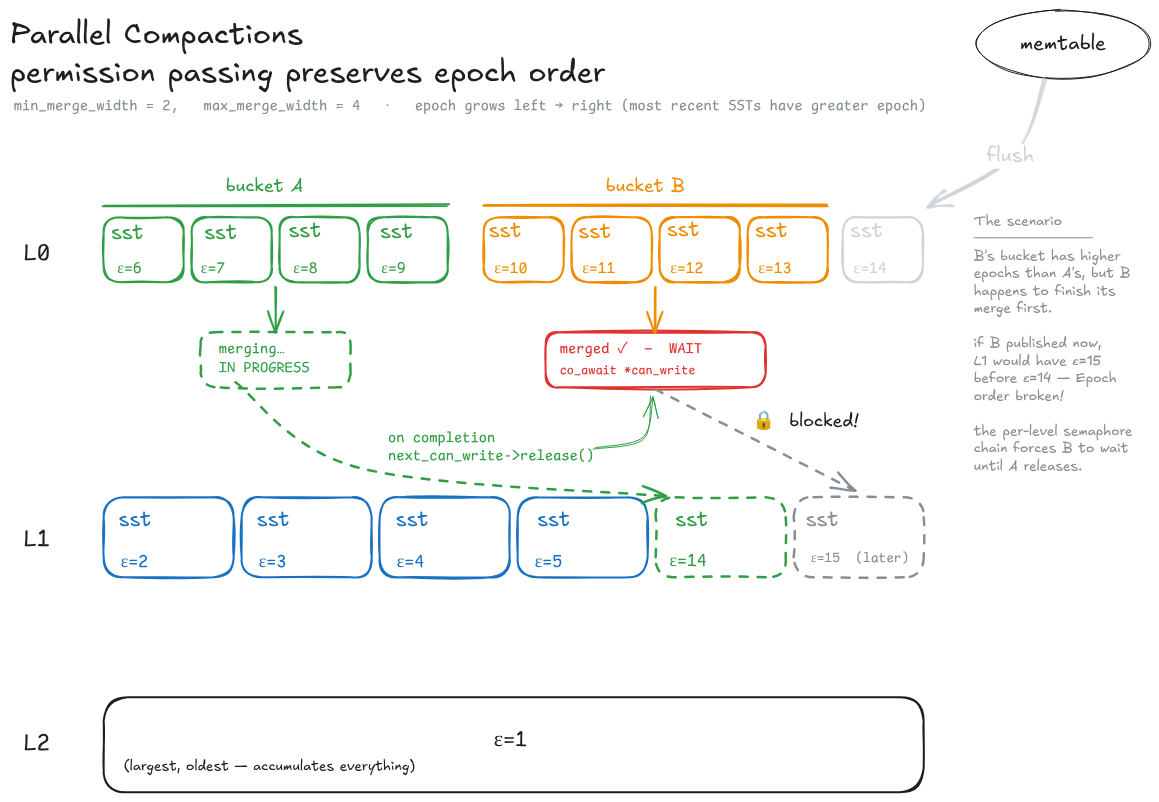
Figure: parallel compactions and permission passing
Applying backpressure¶
The purpose of applying backpressure is controlling the compaction jobs backlog and/or modulating the read amplification.
HedgeDB keeps track of the number of SSTs in L0. If this count exceeds a
threshold (provided from configuration ssts_in_l0_block_write_threshold), a flag
is set. Backpressure from compaction to Writer threads is applied
indirectly, leaving some configurational flexibility and some room for
waiting the SST count to recover within the threshold.
The backpressure flag blocks memtable flushes, which first causes a number of
memtables to temporarily accumulate waiting for flush (up to
max_pending_flushes memtables).
Once this limit is reached, write operations will be hard-blocked when the currently active memtable is full.
Backpressure can be optionally disabled to eliminate very long tails on write-intensive workloads.